Redis学习的惨痛经历
Posted by 付辉 on Monday, January 1, 2018 共4479字我们开发的产品类似于 trivago hotel search,Redis也多用来缓存临时数据。比如将操作频繁的流水数据先存储到redis,之后迁移到关系型数据库做持久化。
旅店查找的功能,前端主要是靠PHP和Symfony Framework开发,后端是Java。本章我们主要强调PHP和Redis的协作,目前它运行的非常稳定,但我们为实现这一步却花费了很大的精力。下面来说我们学习Redis的经历。
前言
起初我们使用的库是 Predis,一直到2013年我们开始使用phpredis (C实现),主要因为二者的性能差异。
在2014年,我们给平台开发了新的特性,导致http 请求短时间内翻了一倍,结果有40%的请求HTTP 500: Internal Server Error.
之后查看日志,发现错误多是redis的连接问题: read error on connection 和 Redis server went away。
| WARN | ... Redis\ConnectException: Unable to connect: read error on connection ...
#0 /.../vendor/.../Redis/RedisPool.php(106): ...\Redis\RedisPool->connect(Object(Redis), Object(...\Redis\RedisServerConfiguration))
#1 /.../vendor/.../Redis/RedisClient.php(130): ...\Redis\RedisPool->get('default', true)
#2 /.../vendor/.../Redis/RedisClient.php(94): ...\Redis\RedisClient->setMode(false)
...
#17 /.../app/bootstrap.php.cache(551): Symfony\Bundle\FrameworkBundle\HttpKernel->handle(Object(Symfony\Component\HttpFoundation\Request), 1, true)
#18 /.../web/app.php(15): Symfony\Component\HttpKernel\Kernel->handle(Object(Symfony\Component\HttpFoundation\Request))
#19 {main}
| 12.34.56.78 | www.trivago.de | /?aDateRange%5Barr%5D=2014-05-20&aDateRange%5Bdep%5D=2014-05-21&iRoomType=1&iPathId=44742... | Mozilla/5.0 (WindowsNT 6.1; Trident/7.0; rv:11.0) like Gecko
Google发现,其他人也遇到过同样的问题: debug read error on connection #70和 read error on connection’ #492.
调试和修复
我们对于问题的起因并没有线索,我们首先做的尝试是Github上所有提到的每个解决思路:
- 修改redis创建连接和执行命令的超时时间,从500ms调整为2.5s
- 禁用php的 default_socket_timeout 设置
- 在redis服务上禁用 SYN cookies
- 检查web服务器和redis间创建的文件描述符数量
- 增加服务器的 mbuffer
- 调整TCP协议中backlog的大小
然而上述修改都没有解决实际问题。我们也试图复现这个问题,但没有成功。可能只有在请求高峰的时候,问题才会出现吧。
在调用redis结束后关闭连接
PHP应用通常是无状态的,一个请求处理结束后,过程中分配的数据都会被释放。当时我们也没有使用php-fpm和redis的长连接机制,所以会为每个请求会创建一个新连接。重新审视代码后发现:我们打开的新连接,从来没有手动关闭过。
这在新版本的PHP中应该不是什么问题。当脚本执行完毕后,PHP会主动帮我们关闭这些连接。然而在老版本中,却可能会导致出现无效连接或内存泄漏的问题。除此之外,主动关闭连接也是一个好的习惯,所以我们修复了这个问题。但这对问题本身并没有什么帮助。
A/B-Testing Redis库
是否我们遇到了phpredis库本身的bug?为了验证这个假设,我们专门A/B-Test比较了phpredis和predis两个库。
当我们将测试的用户量调整到总用户的20%,两个redis库都出现了错误。虽然还是没有什么进展,但却排除了phpredis自身问题的可能。
更新redis
我们和phpredis的维护者取得联系,首先,他们问的是:“你们使用的版本是最新的吗?”一旦你的版本不是最新的,他们就会回答:“请升级到最新版本后重试”。
最终我们升级了版本,但不幸的是,问题仍然没有解决。不过,redis升级到最新了。
调试延迟问题
阅读了相关文档后,我们发现了redis的一个新特性:Redis Software Watchdog,它用来记录执行较慢的操作。虽然官方文档上仍然被标注为实验性功能,但是我们却要尝试一次。
Tip Redis 是单线程的. 每个命令都可能阻塞其他的命令。这很容易被忽视,但却是一些问题的根本原因所在。
我们开启了Watchdog等待几秒之后,撞到了一个巨大bug:Redis服务宕掉了,请查看 Software watchdog crashes redis during rdb save point #1771。之后我们启用了线下的Redis库,继续测试。
我们接下来测试redis的 latency baseline。系统内在的延迟看上去还不错,但redis服务的延迟看起来就比较吓人:
$ redis-cli --latency -p 6380 -h 1.2.3.4
min: 0, max: 463, avg: 2.03 (19443 samples)
之后我们检查了redis的日志,发现redis每隔几分钟就同步数据到磁盘。
...
[20398] 22 May 09:20:55.351 * 10000 changes in 60 seconds. Saving...
[20398] 22 May 09:20:55.759 * Background saving started by pid 41941
[41941] 22 May 09:22:48.197 * DB saved on disk
[20398] 22 May 09:22:49.321 * Background saving terminated with success
[20398] 22 May 09:25:23.299 * 10000 changes in 60 seconds. Saving...
[20398] 22 May 09:25:23.644 * Background saving started by pid 42027
[20398] 22 May 09:26:50.646 # Accepting client connection: accept: Software caused connection abort
[20398] 22 May 09:26:50.900 # Accepting client connection: accept: Software caused connection abort
...
我们使用redis的默认配置,运行在裸机上进行测试的。我们要问的的第一个问题是:**为什么fork一个后台的存储进程要花费约400ms?**在阅读了相关博客和BGSAVE之后,我们终于明白:redis正在fork的存储进程需要复制page table。如果你的redis有很多key,即使是在一台物理机上,执行也会花费很长时间。这个情况已经被加到官方文档:Fork time in different systems.
接下来我们关闭了 Redis snapshots 服务,这减少了超过30%的read error on connection
对于一个需要持久化的实例,snapshpts的使用可能相当棘手。如果有很多请求,且每个请求都做写操作,那么就会有很多的key被修改。这会触发更多的 BGSAVE 操作以及更多的redis拒绝连接现象。因为这最终导致更长的fock时间和redis阻塞。
Tip
回顾你的持久化需求和redis的配置:当请求高峰的时候,应用会修改很多key以及需要做持久化吗?考虑将AOF 或定期地执行
BGSAVE作为标准snapshot的替代,这可能会避免出现连接超时或执行命令超时。
在部分应用场景中,我们并不想去关闭全局的持久化。我们选择关闭这些redis的snapshot,启用cronjobs在具体的时间调用BGSAVE命令。这样就可以避免在请求高峰时触发持久化操作。对于更高的持久化需求,我们更倾向于使用AOF。如果你想要了解更多关于rolling BGSAVE,可以查看:Rolling BGSAVE instead of (pre)-configured save points。
这些改变可以被认为是一个成功。我们减少了error和timeout的问题,但error还是会时不时出现。
为每个业务创建专门的实例
很多团队可能会仅仅使用一个Redis实例,将不同业务或功能的数据存储在不同的db里,这看起来很好,但让我们继续往下说。
我们团队每15分钟会执行一个cronjob,利用Redis Pipelining特性,将MySQL中的数据导入到共享的Redis中。因为Redis是单线程的,导致Redis每隔15分钟就会被阻塞几分钟。
Tip
意识到Redis实例是多个团队或业务共享。不同的使用场景或者执行的命令都可能阻塞彼此。谨记:Redis是单线程的。
我们将cronjob执行的redis实例拆分出来后,之前共享redis的报错明显减少。此外,多个redis实例还可以更好的利用计算机资源。为什么呢?Redis是单线程的,现代的服务器是多核的。
注:在一个redis实例中使用SELECT 和多个db被看做反模式设计。
O(n)时间复杂度
经过上面的调整,我们减少了几乎一个数量级的报错,之后redis一直运行的非常稳定。直到我们给业务增加了新的功能,请求负载持续增加之后,redis连接超时和命令超时又回来了。
基于之前的调查,我们开启了watchdog测试服务的延迟,并查阅SLOWLOG。
在非常短的时间内,我们发现是cronjob内的命令KEYS * 在操作一个大的redis实例时导致的。幸运的是redis文档对每个命令都做了时间复杂度说明。这里有大O符号的介绍。
O(N) N表示数据库中key的数量
Tip
在使用命令时,请务必查阅命令的时间复杂度。O(n)会严重影响redis的性能,通常redis会对一部分命令提供可以替代的指令。比如使用 SCAN来替代KEYS操作。
查阅: 慢指令产生的延迟
我们重新审查代码,优化了超过40%的redis执行命令。之后我们一切正常了。
每个连接创建一个请求
请求量持续增长的同时,我们也一直在优化系统。其中包括优化慢查询、减少单个请求的内存消耗、调整缓存层、添加更多的服务器资源等。但却因为服务器的增多,给我们带来了新的问题。
前面提到,我们的应用是无状态的。具体体现如下:
- 服务器接收到http请求
- 服务器请求第三方服务
- 第三方处理请求,给我们返回结果
- 服务器关闭在2中创建的链接
- 服务器响应客户端请求
这样的模式在前期工作的还行,但增加服务器数量之后,确实可以处理更多的客户端连接请求,但恰恰忽略了第三方组件…
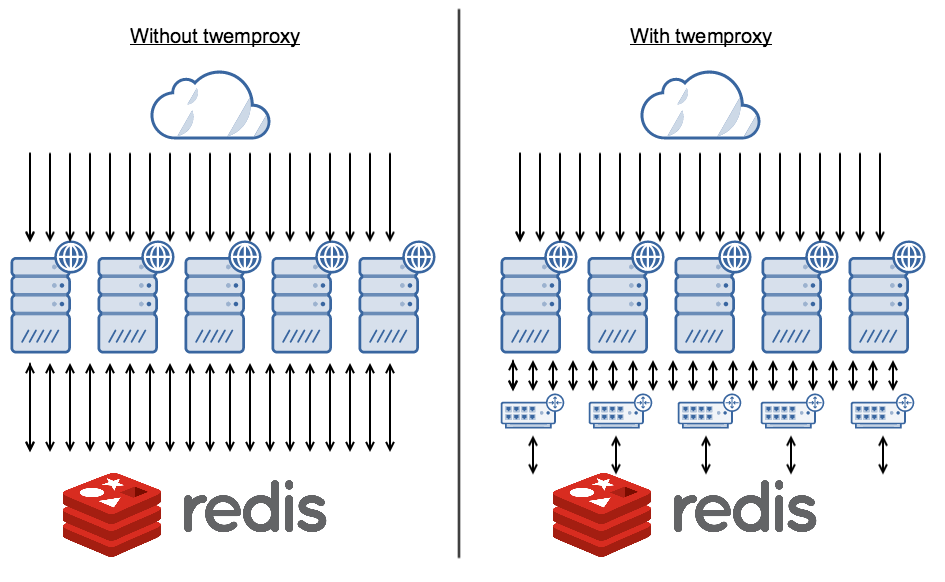
我们的业务对第三方依赖相对较重,50%~75%的请求需要请求第三方来处理。但redis是单线程的,如果大量的客户端试着去连接redis,redis会忙于处理连接请求,而非执行请求的命令本身。这很可能导致慢查询或者服务直接宕掉。上面的图片描述了这种现象,其中每个箭头表示一个http连接。
Tip
考虑在我们服务和第三方之间设置一个代理。如果这个第三方服务(redis)本身有很高的请求,或者多个团队都在使用,设置一个代理会非常不错。不仅可以降低链接负载,还可以充当防火墙,直接拒掉某些命令。
实际上问题已经被前人遇到并解决。方法之一是使用 twemproxy。twemproxy 也是为解决这种问题存在的。在我们的服务上安装twenproxy,我们直接连接twenproxy, 而twenproxy使用长连接请求第三方。服务跟本地代理的交互应该是非常快的,它们使用socket来创建连接。还有一个优点是twemproxy 支持memcached 协议。
之后将twemproxy 引入我们的技术栈,但它本身不是“直接安装运行就一切ok的”应用。我们做了一些小的调整,比如:
-
下载并安装在FreeBSD上
-
增加redis 支持SELECT命令,支持多个db操作
正如之前描述的,redis支持多个db被认为是一个反模式设计。但我们还没有将所有应用都进行调整,所以SELECT还是需要被支持的
twemproxy 能阻止一些本身执行耗时或相对危险的命令,比如 FLUSHALL、 FLUSHDB等。
twemproxy 不足在于:如果你升级redis想去使用一些新的特性,比如GEO commands。 命令需要先被twemproxy 支持,还需要重新部署twenproxy。
数据拆分
我们主要用redis缓存临时数据,而随着用户的增多,只靠单个redis服务必定会成为系统的瓶颈。主要有以下两点:
- 单个redis实例装不下急速增长的数据
- 单个redis服务处理大量的读写请求已经显得很吃力
因此,我们开始着手使用一致性HASH对数据进行拆分。幸运的是,twemproxy原生支持数据拆分。最终的效果如下:
- 降低了每台redis服务的负载
- 在节点故障时,提高了系统的可靠性
第二点对我们显得尤为重要。假设其中一个服务挂掉了,我们的服务仍然可以正常运行。
总结
回顾整个过程会发现,问题本身并不是一个技术问题,而是概念的理解问题。理解了这些问题之后,我们总结一下相对重要的知识点:
- 理解命令的执行方式(单线程)
- 选择合适的持久化方式(bgsave)
- 避免使用单个redis实例多个db的方式, 不同的服务最好使用不同的redis
- 理解执行命令的时间复杂度
- 控制redis服务的TCP/IP连接数(twemproxy)
- 当数据不再适合单个redis时,做好数据拆分(consistent hashing)
当我们做完了文中所描述的调整,基本上就再也没有遇到别的比较大的问题。但还应该明确:在生产环境中,我们还是有很多别的事情需要去关注:
- 主从数据同步
- Redis Sentinel
- 正确的内存回收策略
- redis安全或可能的漏洞
- 合适的监控和报警