Memcached遇到的json_decode问题
Posted by 付辉 on Sunday, January 21, 2018 共2445字Memcached 是一个高性能的分布式缓存系统,使用Key-Value存储字符串和对象。通常来说,它主要用于缓存从数据库中检索到的数据以及第三方服务的数据等。简单的说,它可以提升服务器的性能。几乎所有的程序语言都可以接入它的API。如下例子所示:
public function getYouData(string $key) {
$yourData = $memcached->get($key);
if (!$yourData) {
$yourData = $yourDb->getAll();
$memcached->set($key, $yourData);
}
return $yourData;
}
在trivago, 我们使用Memcached做缓存层,而且我们对外仅提供缓存接口。开发过程中,程序员不需要考虑缓存的内部实现,仅仅知道如何调用接口就可以了。目前,该API在PHP的代码库中几乎都有使用。我们使用Memchached的场合已经相当多了,随着每次新版本发布,使用量还在增加。
一天,系统日志文件里几乎全是Memcached的报错,get方法调用失败,导致所有的请求直接打到了数据库上。当然,在巨大负载的情况下,这些请求最终也失败了。最终,我们遇到了影响trivago整个平台能正常运行的问题。
那么到底发生了什么?为什么Memcached开始出问题了?
Botnet也就是我们所说的僵尸网络,是指采用一种或多种传播手段,将大量主机感染bot程序(僵尸程序),从而在控制者和被感染主机之间所形成的一个可一对多控制的网络。
原因是来至于200个国家,70K独立IP的网络攻击,直接导致当时负载飙升到平时的40倍。10分钟后我们的蛛网节流机制被触发,攻击的影响被慢慢减弱。
攻击造成Memcache的网络带宽饱和,直接原因是其中一个库的get/hit请求引起的。查看发现,这个库已经使用了大约4GB内存。很明显,这里有一些问题。
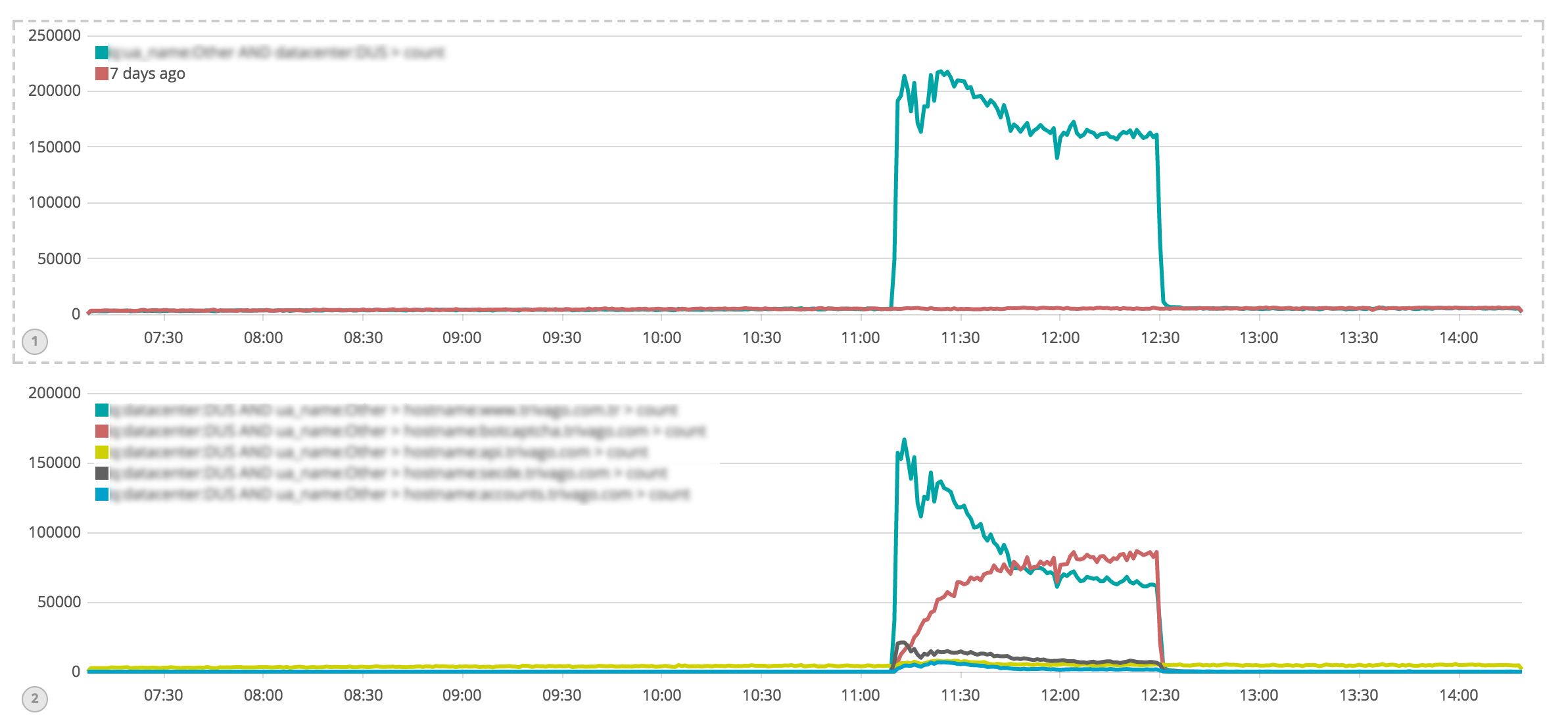
之后,我们对缓存记录了更加详细的日志。当然,我们之前也记日志,只是无法从现有日志中发现,究竟是哪些key消耗了大部分内存。因此,我们特别对value的占用内存大小做了额外的记录。
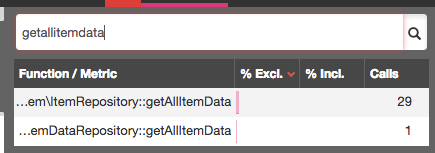
一天后,通过log记录,我们终于发现了这‘怪物’:ItemRepository 下的静态方法getAllItemData ,缓存的数据平均有10M左右。
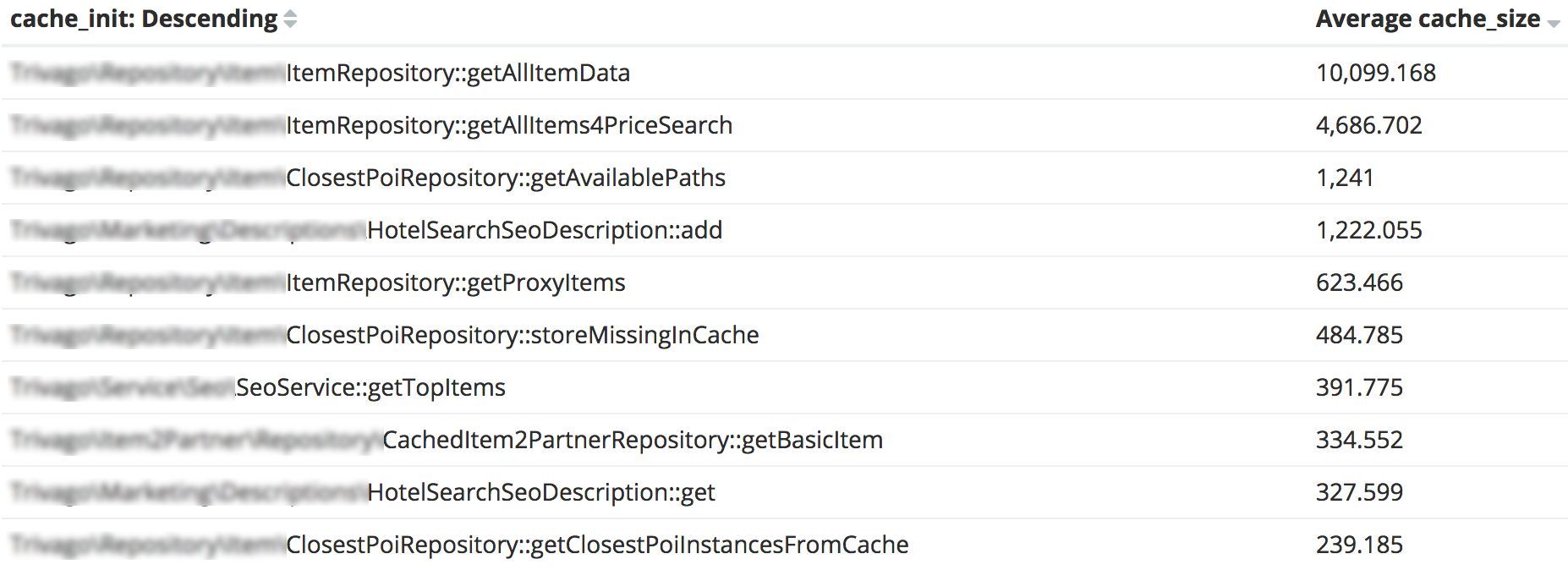
仅仅只是名字,听起来就怪吓人的吧?更可怕的是,这个方法是2014年写的,从2015年起就再也没有被改动过。根据Blackfire的性能剖析,每加载一个页面就会调用30次getAllItemdata 方法。
接下来,我们单独对这个方法debug,为什么缓存的值会这么大?结论是:我们正在使用默认的Memcached serialization方法,更精确的讲,是原生的PHP serialize / unserialize方法(自从我们迁移到PHP7,我们就停止使用igbinary 的扩展,因为两者结合的时候会出现问题,因此序列化的工作又重新交给了php)。这也就意味着除了存储必要的数据之外,还需要额外存储对象的类名、属性等信息。
问题很明显了,这调整起来应该也非常简单。将php serizlization 成某种更加紧凑的数据存储格式。
当前的环境,使用igbinary的话,改动会非常大。因此我们考虑使用JSON或Protobuf,但是基于灵活性、快速实现的考虑,我们最终决定使用json,它是一种简单、轻量的数据存储格式。
JSON是无模式的数据结构,对数据进行编码非常方便,但解码的时候,需要将数据映射到对应的类上。
//people是一个类,json_encode不会编码对象的私有变量
$zhangsan = new people('zhangsan', 'boy', '23')
$json = array('people' => $zhangsan);
$jsonEncode = json_encode($json);
$jsonDecode = json_decode($jsonEncode);
我们考虑是否要使用一个外部的扩展:Symfony组件Serializer,然而经过一系列基准测试之后,我们还是决定手动实现数据编码和对象的映射关系。主要还是出于对PHP性能的考虑,对我们而言,手动实现也仅仅只是额外调用一次内部实例对象,并且,我们还可以灵活的对它进行调整。
- 实现json_ecode方法,编码从数据库检索到数据
- 改变缓存中key的前缀,确保跟之前的不存在冲突
- 增加json_decode方法,用于从Memcached中获取数据
- 将数据转换成对应的PHP实体或对象
听起来很简单,是吧?但我们运行测试时,json_decode持续地返回错误:语法错误、控制字符错误、或者错误的UTF-8格式。
ok?会不会是因为:我们从DB中检索到的数据,含有特殊的国际字符,又或者存储之前应该encode处理一下。
于是我们尝试使用json_encode的属性JSON_UNESCAPED_UNICODE,无效!然后又依次尝试了别的方法,诸如utf8_encode和mb_convert_encoding 。难过的是,我们也不知道从DB中取出的数据的编码的格式,因为有时候是ASCII、有时候是UTF-8。我们大概花费了2天时间,也没有找到问题的原因,几乎陷入了绝望。
我们存储的数据对象,结构是一个多维数组。所以我们决定一层一层对其进行debug。首先,我们只保留数组的最外层数据,对其进行测试,结果json_decode方法正常了。
貌似找到了问题的关键,问题就出在对象内部的子数组上。接下来,我们一层一层去验证json_decode是否可以正常工作。但即使我移除子对象的所有属性,以至于这个数组仅仅包含一个空对象,json_decode仍然失败。这就非常可疑了,我们开始怀疑这并不是数据本身导致的问题。接下来我们做了更多的测试,发现数据被缓存的接口错误处理了。
好,最终定位到问题了。问题肯定是Memcached对数据的处理导致的。
我们查阅了关于Memcahced, Json encode/decode, 和出现的语法错误,发现Github上的一个Memcached debug的描述:当Memcached存储超过2000字符的json encode的字符串时,对其decode的时候会发生错误。我们立马检查了我们Memcached的版本号,这个版本刚好包含这个bug。幸运的是,新的版本已经修复了这个问题。于是我们将Memcache更新到 3.0.2之后,decode终于正常了。
原文地址:http://tech.trivago.com/2017/12/19/how-trivago-reduced-memcached-memory-usage-by-50/