Protobufs在Logstash中的应用
Posted by 付辉 on Tuesday, January 30, 2018 共1849字ELK 分别是Elasticsearch、Logstash、Kibana技术栈的结合。主要解决的问题在于:系统服务器多,日志数据分散难以查找,日志数据量大,查询速度慢,或者不够实时。
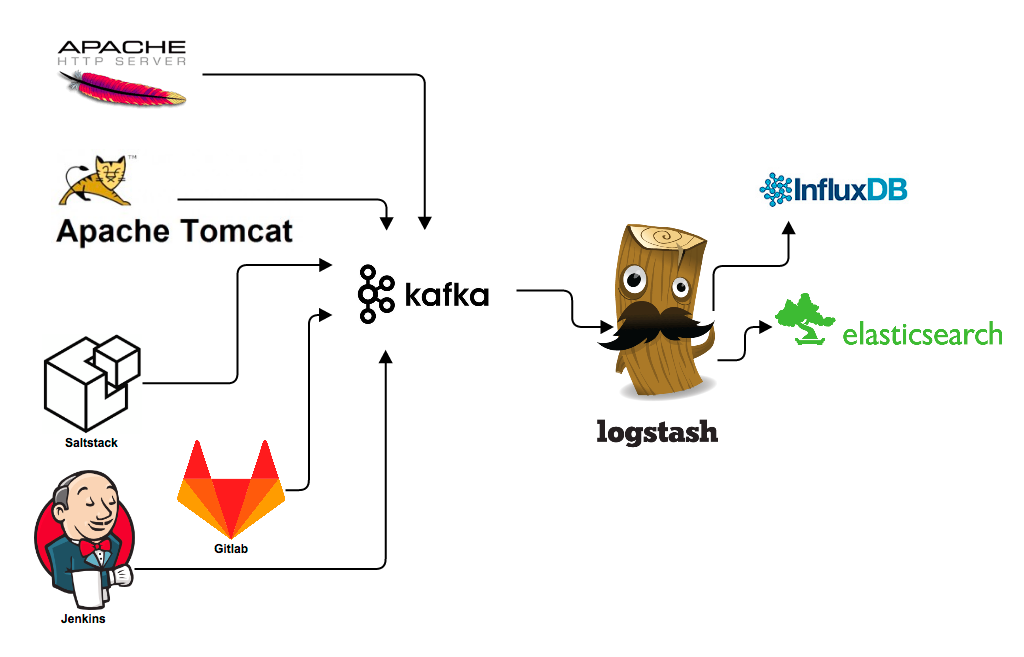
在trivago,我们主要依靠ELK来处理日志。我们通过使用Kafaka,将服务器的访问日志、错误日志、性能基准数据及各种各样的诊断日志,传递给Logstash,Logstash处理之后将日志存放到Elasticsearch。在数据传输中,我们更倾向使用protocol buffer对数据进行编码。这篇博客,我们将主要介绍如何使用Logstash来解析protobuf编码的消息。
相比无模式的JSON格式,Protobufs是一种有模式、高效的数据序列化格式。我们在Kafaka中传输的数据,很多都在使用Protocol Buffers进行编码。它的优势就在于:首先,编码后的数据size明显要比其他的编码方式要小。以JSON编码举例,消息体中不仅仅包含实际数据,还有对应的Key值及很多的中括号。对于文档结构基本不变的数据,传输中包含这些附加信息,是一种资源的浪费。当发送端和接收端对交互的文档结构达成一致后,传输过程还携带这部分结构信息就显得多余。在整个日志处理过程中,该部分消耗的资源是可以被节省下来。其次,消费者所处理的数据,数据格式都是约定好的,完全不会像JSON一样,莫名奇妙多出一个字段。同时,给数据字段的理解产生误解。
不开心的是,Logstash不支持Protobufs编解码。目前,它支持纯文本、JSON格式和其他别的消息格式。因此,我们决定自己实现这部分功能。
如何写Logstash的编码器
写一个Logstash插件是相对容易的,你只需要掌握一些基本的Ruby知识。Ruby语言天生直观简单,你很可能在查看示例代码的同时,就将它学会了。对初学者而言,tryruby.org是很不错的学习网站。你需要在电脑上安装Jruby,其他环境部分请参照elastic’s documentation。当你发现github上codec项目是空的时候,请不要困惑,请你clone JSON codec或plain codec来代替。通过这个过程,你将会了解到现存的插件是如何开发的,同时,你还能掌握ruby的相关知识。
校验JAVA环境变量是否设置成功
java -version
获取protobufs
最后,你下载logstash-codec-protobuf插件来解码protobuf消息。要使用这个插件,你需要一些proto文件和使用该proto格式编码的数据。如果这个proto文件已经在别的工程中使用了,那么你就仅仅需要创建proto文件的Ruby版本。如果这完全是一个新的项目,那么你可能需要先从Google’s developer pages了解一下proto 文件的语法规则,找到适合你项目的工具链,然后编译proto文件。
列举一个proto文件的sample,使用Go编码:
//使用proto3, 不支持optional选项
syntax = "proto3";
package tutorial;
message Person {
string name = 1;
int32 id = 2; // Unique ID number for this person.
string email = 3;
}
安装插件
从rubygems下载logstash的插件,执行如下命令:
bin/plugin install PATH_TO_DOWNLOADED FILE
这个解码器支持Logstash 1.x和2.x版本。
创建Ruby版本的protobufs文件
假设下面的 unicorn.pb文件是我们定义的proto文件,我们将要使用它去解码消息:
package Animal;
message Unicorn {
// colour of unicorn
optional string colour = 1;
// horn length
optional int32 horn_length = 2;
// unix timestamp for last observation
optional int64 last_seen = 3;
}
下载ruby-protoc的编译器,然后运行:
ruby-protoc unicorn.pb
编译器最终会使用后缀.rb生成一个新的文件,比如unicorn.rb.pb。它就是我们定义的proto文件的Ruby版本。
#!/usr/bin/env ruby
# Generated by the protocol buffer compiler. DO NOT EDIT!
require 'protocol_buffers'
module Animal
# forward declarations
class Unicorn < ::ProtocolBuffers::Message; end
class Unicorn < ::ProtocolBuffers::Message
set_fully_qualified_name "animal.Unicorn"
optional :string, :colour, 1
optional :int32, :horn_length, 2
optional :int64, :last_seen, 3
end
end
现在,你需要在配置中指定这个文件的路径,以便Logstash可以知道它。
Logstash配置
你可以在Logstash的input中使用该编解码器。在下面例子中,我们使用kafka作为数据源。使用protobuf读取消息的配置如下:
kafka
{
zk_connect => "127.0.0.1"
topic_id => "unicorns_protobuffed"
codec => protobuf
{
class_name => "Animal::Unicorn"
include_path => ['/path/to/compiled/protobuf/definitions/unicorn.pb.rb']
}
}
一个更加复杂的例子,可以参考documentation on GitHub。现在启动你的Logstash,让我们看看它是如何工作的。
文章涉及的内容相对较多,原计划将实现的细节最佳到文章结尾,但发现对Logstash和Ruby还是理解的不够,所以决定,后面的文章继续对这篇文章介绍。
原文地址:Better Log Parsing with Logstash and Google Protocol Buffers