Database Sharding
Posted by 付辉 on Saturday, March 9, 2019 共1521字Sharding
可以简单地认为Sharding就是对数据进行分组的过程,即将整个大的数据集按照某种规则分割成多个小数据集。类似于网站服务,针对不同的服务,提供服务的链接地址也不相同,而这其实也是一个Sharding的过程。在业务层实现的Sharding,关键就在Route的过程,即将具体的数据请求,发送到对的数据集上。
基本要求:Sharding前后执行相同的查询,返回的结果也相同。
Why Sharding
在一些本地缓存的开发中,如果以map的形式存储数据集,因为该类型不支持并发操作。所以,在读写操作时就需要对map进行加锁,。可想而知,每次操作都加锁、解锁,而读写缓存又是一个高频操作,性能当然上不去。解决的思路就是对数据集进行Sharding操作,将整个数据集拆分成多个小块数据集,这样分别对小块数据集进行加锁、解锁,性能就提高了不少。
如果数据集过大,表的检索性能会越来越低。而如果对数据集进行分片,对分片数据并发检索,以及将某些分片数据直接加载到内存,都可以极大提高操作的效率。
数据均匀分布
拿博客网站举例,老用户发布的博客肯定要多于新注册的用户。那么,在对博客记录进行分表操作时,就需要考虑数据均匀分布的问题,避免老用户都分布在一张表内,造成某张表数据额外大。
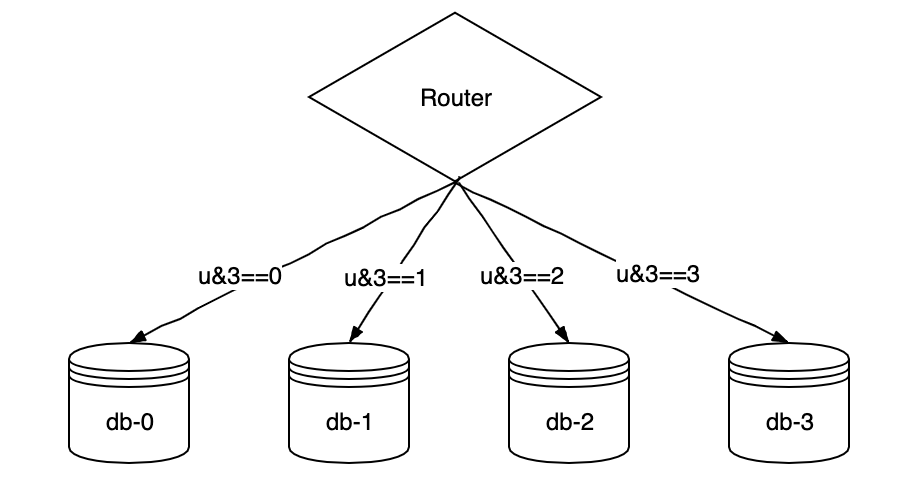
解决的办法很简单,即对Sharding Key先做Hash处理,然后再实现数据Sharding过程。比如在系统设计初期,我们考虑基于用户UID将博客数据拆分成4个表。最基础的分表策略:
// 最终的结果就是blog_0, blog_1, blog_2, blog_3
tablePrefix := blog_%d
tableName := fmt.Sprintf("%s", uid&3)
业务类型
分表过程需要结合实际项目,不同的业务场景,需求千差万别、更别说底层的数据了。拿购物场景来说,以商铺为分表Key,将同商铺的交易数据存储到一起,跟以用户为分表Key,将同用户的交易数据存储到一起。这两种情形完全不同,而这也将决定项目后期数据统计的方式。
所以分区的根本再于业务要执行的具体数据操作,要知道跨分区来之行Join之类的操作,不仅处理麻烦,性能也是问题。
服务化
实际项目中,按单一维度划分业务数据几乎是不可能的。比如上面说到的购物场景,商铺是一个维度,用户同样也是一个维度,当然,产品的类型还是一个维度。
这种情况下,我们一般选择将项目拆分成多个微服务,划分各个微服务间操作数据的边界范围。而服务与服务间的数据交互都通过调用API来实现。
需要注意的是,服务拆分一定要从具体业务来考虑,尽可能将相关的数据放在一起,提高检索性能,避免每次操作都需要通过网络来发送数据。
唯一ID
将数据集划分为多个分区后,基于不同的业务,查询场景也会面临各种各样的问题。比如在博客网站中,假设我们基于用户做了Sharding分表,而查询需求是:按照博客的发布时间顺序来展示列表。所以,这样的分页查询会异常痛苦。假设列表每页展示20条记录,那么代码就需要从每张表中都取出最近的20条记录做merge处理。如果Sharding的个数足够多,那简直无法继续了。
-- 获取最新的20条发帖记录。如果要翻页的话,将Now替换为上一批数据的最早时间
select * from blog_0 where create_time < Now() order by id desc;
select * from blog_1 where create_time < Now() order by id desc;
select * from blog_2 where create_time < Now() order by id desc;
select * from blog_3 where create_time < Now() order by id desc;
正确的处理方式是创建一张关系表,记录所有博客元信息。而上述分页操作都基于该关系表来实现。但Sharding中的各表都有各自的自增主键,都从1开始自增,这就导致各个表中存在相同的标识符,再关系表中无法做区分。解决的办法大致有两种:
-
生成全局唯一的
UUID,或者稍加改造,生成全局自增且占内存小的唯一ID。 -
在关系表中不仅保存分区表的主键ID,还额外保存分区ID,通过这两个ID来唯一标识一条记录。
参考文章: