数据一致性(二)
我们流连于事物的表象,满足浅尝辄止的片刻欢愉,却几乎从不久留。我们在人生的道路上争先恐后,却吝于用片刻思考目标和方向。
概述
至今没有接触过MySQL多主的情况,即存在多个MySQL实例同时负责读写请求(抛弃只读库)。思考后认为:没有这么实现的技术难点在于:数据的一致性得不到保证。此外,还会涉及:
MySQL采用自增主键索引的话,多主之间的数据同步简直是灾难。- 内部锁机制的优势大打折扣,跨主库间的锁应该也是灾难级别的吧。
那么支持分布式的其他数据库又是怎么搞定这个问题的呢?比如Cassandra,多个节点之间可以同时处理读写请求,那么它是如何处理节点间数据同步以保证一致性的呢?
MySQL数据的一致性
We think this is an unacceptable burden to place ondevelopers and that consistency problems should be solved at the database level
细细想想,MySQL自身实现的数据一致性也是相当复杂的。以Innodb举例,如果通过普通索引执行查询,首先获取到的仅仅是主键索引,后面还需要通过主键索引来获取完整的记录。查询如此,更新亦如此。
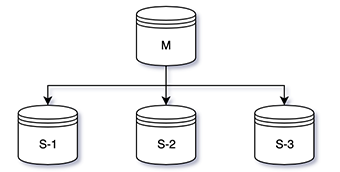
Master-Slave模式
通常情况下,MySQL部署都是一主多从。Master作为更新DB的入口,而Slave的数据通过binlog来进行同步。所以大胆想一想,有没有可能出现一种情况(假设id=1记录原始的name值为neojos):
## 第一次同步数据
update s-1 set name="neojos-1" where id = 1; ## 失败
update s-2 set name="neojos-1" where id = 1; ## 成功
update s-3 set name="neojos-1" where id = 1; ## 成功
## 第二次同步数据
update s-1 set name="neojos-2" where id = 1; ## 成功
update s-2 set name="neojos-2" where id = 1; ## 失败
update s-3 set name="neojos-2" where id = 1; ## 成功
最后,数据库从某一个时间点开始,Master和Salve的数据会变得不一致了当然不可能,MySQL在数据同步上做了非常硬的约束。包括Slave_IO_Running、Slave_SQL_Running以及Seconds_Behind_Master等。
并发下的数据一致性
MySQL并发下的数据一致性是通过锁来保证的。并发的请求,谁先拿到X锁,谁就有修改的权限。锁类似扮演了一个操作版本号的作用。
X |
IX |
S |
IS |
|
|---|---|---|---|---|
X |
Conflict | Conflict | Conflict | Conflict |
IX |
Conflict | Compatible | Conflict | Compatible |
S |
Conflict | Conflict | Compatible | Compatible |
IS |
Conflict | Compatible | Compatible | Compatible |
理解冲突
以数据读取和写入为切入点,引申出两个工作中可能可能遇到的冲突问题,并通过加锁以及设置版本号来避免冲突的发生。
Go的并发问题
下面是一个简单的Go Test代码问题:求1-100的累加和。我们通过Goroutine和最普通的两个方式分别计算。同时,在代码的末尾对两种方式的计算结果进行了比较并打印输出。
// 输出结果每次都是变化的。其中一次:5499 != 5050
func TestSum1To100(t *testing.T) {
result1 := 0
result2 := 0
// 并发的进行计算
var wg sync.WaitGroup
for i := 1; i <= 100; i++ {
wg.Add(1)
go func(m int) {
defer wg.Done()
result1 += m
}(i)
}
// 正常的For循环
for i := 1; i <= 100; i++ {
result2 += i
}
wg.Wait()
if result1 != result2 {
t.Fatalf(" %d != %d", result1, result2)
}
}
并发情况下,每个goroutine在读取result1到result1=result1+1的过程中,无法保证result1不被别的goroutine所修改。
从MySQL解决问题的思路来考虑:加锁。我们要对读取result1到result1=result1+1的过程进行加锁,保证这个过程是同步的。
一对多情况
在国内第三方支付(微信/支付宝)场景中,用户是否支付了某个商品,是通过服务端接受第三方异步回调通知的方式,来作为判断依据的。而回调通知存在相应的重试策略,而且都要求幂等处理。
假设下面一个场景,我们创建了以user_id为唯一索引的表(user_pay)用于统计该用户支付成功的次数,以及用户支付明细表(user_pay_detail),两者是一对多的对应关系。服务端每次收到第三方的支付回调,都在user_pay_detail追加一条新记录,同时相应的调整user_pay的信息。
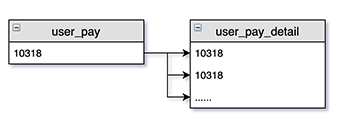
如果在回调过程中,存在这样一个场景:在03-02号收到了支付回调通知,对数据进行了调整。而在03-15号的时候却又收到了02-01的回调通知(该通知已经在02-01处理过了)。如何保证user_pay中的数据不会被多加一次?
当然,解决办法非常简单。其中一个解决办法便是:在user_pay中记录上一次回调通知的时间戳,以此作为这行记录的版本号,后续也只有大于该版本号的通知才会被处理。
CAP
了解一下分布式的环境下的CAP定理,这里主要强调一下:Consistency。在分布式系统中,存在多节点同时对外提供读写服务,数据存储多份副本的情况。那么,这些节点在同步数据的过程中,可能会因为网络或者机器的原因导致数据同步失败,从而造成各个节点数据不一致的情况发生。

Last-write-wins
Last-write-wins表示在对一条记录应用多个修改的时候,最后的改动会覆盖掉之前的操作,返回给客户端的记录都以最后一次的改动为准。
这也是分布式系统解决冲突的一个策略。基于timestamp的版本控制系统,比如HBase。每次操作都会给记录附加一个timestamp的版本号。这样一来,当某些数据发生冲突时,我们就可以简单的认为最新的记录是准确的。
但实际上,基于Last-write-wins的策略并不一定是正确的。比如多个节点对同一条记录进行修改。首先,节点服务上的时间钟不是严格相等的;其次,客户端发出的请求时间,跟到达节点服务的时间也是没有任何联系的。
vector clock
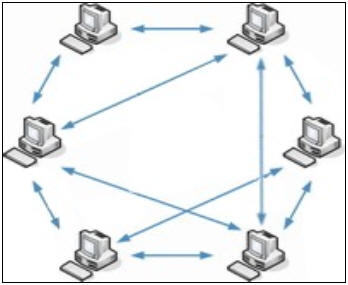
先说一下需要用到向量时钟的场景。我们在写数据时候,经常希望数据不要存储在单点。如db1,db2都可以同时提供写服务,并且都存有全量数据。而client不管是写哪一个db都不用担心数据写乱问题。但是现实场景中往往会碰到并行同时修改。导致db1和db2数据不一致。于是乎就有人想出一些解决策略。向量时钟算是其中一种。简单易懂。但是并没有彻底解决冲突问题,现实分布式存储补充了很多额外技巧。
文章vector clock 向量时钟算法解释的实在是太完美了,这里就不冗余解释了。下图是一个分布式服务的示例,各个节点都可以提供读写服务。
Cassandra的思路
KV类型的分布式数据库在存储对象时,存储的是对象序列化的结果。举个例子:
- 有一个
jbellis的对象,初始值为{'email': 'jbellis@example.com', 'phone': '555-5555'},我们认为这个初始值为V0 - 之后修改了
jbellis的邮件地址,这时候值记作V1,{'email': 'jbellis@illustration.com', 'phone': '555-5555'}。但因为网络或其他问题,在同步数据到其他节点的时候失败了,导致该修改仅仅被成功写到了其中一个节点上 - 接着,我们更新
jbellis中的电话信息。但我们读取到的jbellis是V0,所以,修改后的V3为{'email': 'jbellis@example.com', 'phone': '444-4444'}
从Last-write-wins的角度考虑,我们采纳了V2的值,而丢弃了V1。简单直接,但不一定正确;
从vector clock的角度来看,当同步V2到其他节点时,就会发生数据冲突,因为当前节点的版本为[V0, V2],而其他节点的版本是[V0, V1],这时候就需要依靠具体的冲突解决策略。
而Cassandra在存储数据结构上做了处理,将对象中email和phone单独存储,并给每个column都指定一个独立的timestamp作为版本号。这样,当冲突发生时,就可以简单运用Last-write-wins策略了。
A column is the basic data structure of Cassandra with three values, namely key or column name, value, and a timestamp. Given below is the structure of a column.

总结
实事求是,具体问题具体分析。请记住,对你而言,上面这些方法可能都不合适。
参考文章: