Go 调度模型(三)
Posted by 付辉 on Sunday, April 14, 2019 共1357字
别抱怨,也别自怜,所有的现状都是你自己选择的
Scheduler Trace
GODEBUG 变量可以控制运行时内的调试变量,参数以逗号分隔,格式为:name=val。本文着重点在调度器观察上,将会使用如下两个参数:
-
schedtrace:设置 schedtrace=X 参数可以使运行时在每 X 毫秒发出一行调度器的摘要信息到标准 err 输出中。
-
scheddetail:设置 schedtrace=X 和 scheddetail=1 可以使运行时在每 X 毫秒发出一次详细的多行信息,信息内容主要包括调度程序、处理器、OS 线程 和 Goroutine 的状态。
GODEBUG=schedtrace=1000 go run ./main.go
GODEBUG=schedtrace=1000,scheddetail=1 go run ./main.go
以下面的输出为例:gomaxprocs是当前的GOMAXPROC值,runqueue为全局可运行队列的长度。
➜ one-case go version
go version go1.13.4 darwin/amd64
➜ one-case GOMAXPROCS=1 GODEBUG=schedtrace=1000 go run ./main.go
SCHED 0ms: gomaxprocs=1 idleprocs=0 threads=3 spinningthreads=0 idlethreads=0 runqueue=0 [2]
# command-line-arguments
SCHED 0ms: gomaxprocs=4 idleprocs=1 threads=4 spinningthreads=1 idlethreads=0 runqueue=0 [1 0 0 0]
# command-line-arguments
SCHED 0ms: gomaxprocs=1 idleprocs=0 threads=3 spinningthreads=0 idlethreads=0 runqueue=0 [2]
SCHED 0ms: gomaxprocs=1 idleprocs=0 threads=3 spinningthreads=0 idlethreads=1 runqueue=0 [0]
SCHED 1009ms: gomaxprocs=1 idleprocs=1 threads=9 spinningthreads=0 idlethreads=2 runqueue=0 [0]
SCHED 1008ms: gomaxprocs=1 idleprocs=0 threads=3 spinningthreads=0 idlethreads=1 runqueue=0 [0]
Memory Allocator Trace
GODEBUG 中指定输出申请内存的 trace 信息:
GODEBUG=allocfreetrace=1,scheddetail=1 go run ./main
Spinning thread
调度器总是试图让M尽可能多的执行G,来达到充分利用CPU的目的。在抢占式调度中,OS线程之间频繁的传递G,会增加系统延迟。此外,线程还会阻塞在系统调用上,这也会增加额外的开销。为了减少线程间传递G的影响,Go调度实现了Spinning threads。一个线程是Sponning threads:
- 绑定P的M正在获取可运行的G
- 没有绑定P的M正在试图获取P
- 当存在一个可执行的G,但是没有空闲的P以及没有自旋的线程时,调度器会创建一个自旋的线程。
系统在任一时刻,最多有GOMAXPROCS自旋的M。当一个新的G被创建,或者M被阻塞时,调度器会确保至少存在一个自旋的M。
执行模型
前面的章节中,我们介绍了操作系统的调度模型:N:1、1:1、M:N。而Go采用了更高效的方式M:N。从进程的角度来说,线程是最小的调度单元。而Go的模型下,可以把P作为最小单元的调度单元,即在单个线程上运行的Go代码。
下图展示了Go的最小调度单元模型。其中的有两个线程,各维持一个P对象,而且正在执行一个G代码。为了运行G,M必须首先持有P对象。图中灰色的G表示还没有被执行,等待被调度。它们被组织在P的一个runqueues的队列中,当M创建新的Goroutine时,对应的G就会被追加到该队列的末尾。
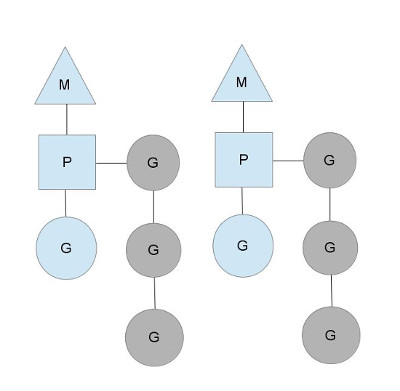
阻塞模型
为什么要引入P结构,直接将runqueues放在M中,不就可以摆脱P了吗?当然不行,它存在的意义还在于:当M因为其他原因被阻塞时,我们需要将runqueues中的G交给别的M来继续处理。因为线程不可能既执行代码,又阻塞在系统上。
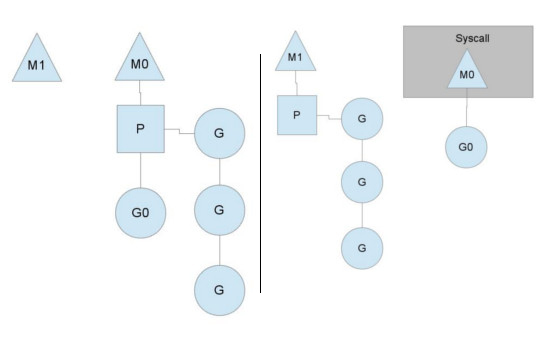
如上图所示,当M0阻塞在系统调用上时,它会放弃自己的P,以保证M1可以继续执行其他G。当M0系统调用返回时,M0为了继续执行G0,就必须尝试重新获取P对象。正常的执行流程是:它尝试去偷其它线程的P,如果不行,就将G0放到全局的runqueues中,之后进入休眠。
当P本地的runqueues运行完之后,M会去全局队列取G来执行。同时,全局队列的G也会被间歇性检查,否则里面的G可能永远都得不到执行了。
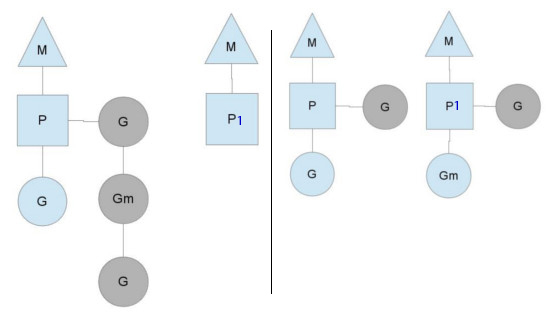
偷G模型
当runqueues分布不均衡时,可能存在其中一个M执行完了本地的P,而其他P的本地队列还有很多G等待被执行。如图所示,为了去继续运行Go代码,P1首先会尝试去全局队列获取。如果全局队列没有,那么它就会随机从别的P去偷一半回来。这样做也是用来保证所有线程都一直有工作可以做。
参考文章: