分布式会话跟踪系统架构设计与实践
Posted by 付辉 on Sunday, August 25, 2019 共1278字调用链trace系统可以帮助技术人员快速的定位问题,查看整个请求的调用链路,及各个链路的耗时情况。方便技术人员针对性的对服务进行性能优化。
概念
参考调用链trace的设计分析的介绍,trace系统的要素包括:traceId、spanId、annotation。
traceId:贯穿整个调用链路,通过traceId来关联链路的所有相关日志spanId:标识单次请求调用annotation:记录请求调用的附加信息
简化trace日志设计
在调用链trace的设计分析文章中,系统log设计相对复杂,先从最简单的入手开始了解。
微服务A、B、C之间存在相互调用关系,我们为每次请求记录一条log。通过log中的parnetID来确定调用的层级关系,通过spanID来唯标识一个独立请求,通过traceID来收敛所有相关日志。最终就可以确定请求的调用层级结构。
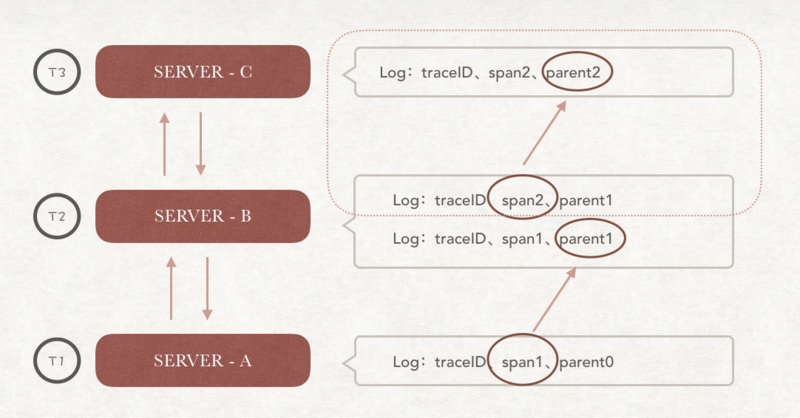
从SERVER-C可以看出,日志记录在C服务的总处理时间。在结合SERVER-B的发起请求时间,可以初略得出span2的网络耗时。
特别注意一下span的变化。当向下游服务发起请求时,需要生成一个新的span,并将该span的父节点设置成上一步生成的span。SERVER-B请求SERVER-C描述的就是这个过程。
而当服务收到一个请求时,只有当请求没有关联新的span时,才需要生成一个span。SERVER-C收到SERVER-B的请求,描述的是这种情况。
Other日志设计
调用链trace的设计分析文章又是如何实现的呢?文章给出的调用关系如下:
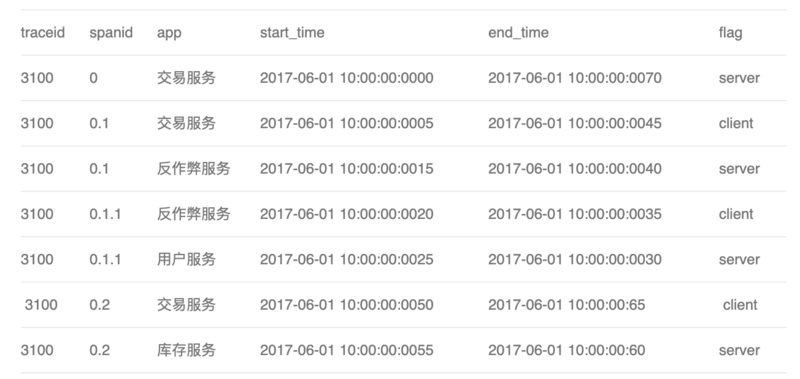
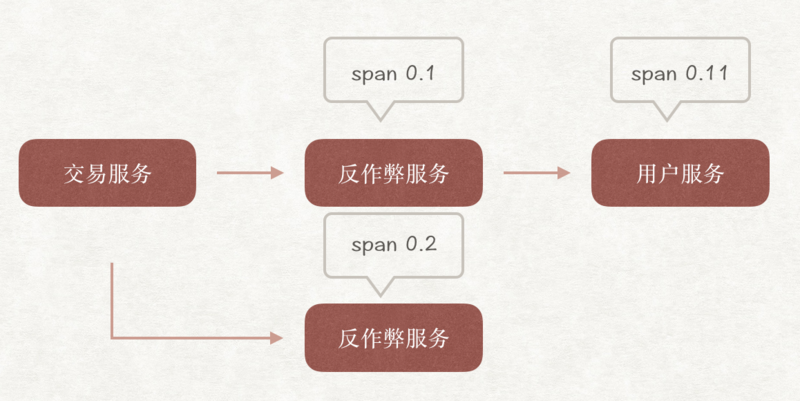
两者的区别在于:确定层级的方式不同。这里通过span值的创建规则来确定调用的层级。而前者是通过借助parentID来确定层级。
Annotation
通过基于Zipkin的Thrift服务RPC调用链跟踪文章了解到,存储span信息可以通过Annotation和BinaryAnnotation来实现。
Annotation用于记录某个时间点发生的event,对event的触发时间、类型有明确规定。而BinaryAnnotation则用来记录用户自定义的信息。也就是说:前者是公用的,后者是个人用的。
因为反向代理路径重写的原因,客户端请求的path和服务端提供服务的path可能不相同,如果你想在系统中定位这种情况,那么你就可以将http.url追加到BinaryAnnotaion属性中。
了解一下BinaryAnnotation日志存储的数据内容:
{
"app": "app", //所属应用
"ip": "ip", //ip地址,冗余信息
"key": "key", //key, 可以设为存储用户session的key, 如果是用来传递用户session信息的, 可以统一约定为: session_id
"mname": "mname", //方法名
"pid": "10000", //进程id,冗余信息
"sid": "sid", //spanId
"sname": "sname", //服务名
"tid": "tid", //traceId
"timestamp": 1449038780194, //产生的时间戳, 长整型, 精确到毫秒
"type": "type", //类型,用来区分是记录异常的还是业务流程的等等, 默认是'common'即可
"value": "value" //如果是传递用户session信息 ,可以直接写在该字段中.
}
参考地址: