IO多路复用
Posted by 付辉 on Friday, September 20, 2019 共3974字引言
结合文章我读过的最好的epoll讲解,认识select和epoll的基本工作原理。
假设:启动一个WEB服务,服务端每accept一个连接,在内核中就会生成一个相应的文件描述符。现在服务器成功建立了10个连接,我们需要知道其中哪些连接发送过来了新的数据,然后对其进行处理和响应。
通过一个基本的循环,我们就可以实现:
while true:
for x in open_connections:
if has_new_input(x):
process_input(x)
这也是我们常用的“轮询”模式,不停的询问服务器“数据是否已经准备就绪”,而这非常浪费CPU的时间。
为了避免CPU的空转(无限的for循环),系统引入了一个select的代理。这个代理比较厉害,可以同时观察许多流的I/O事件。在空闲的时候,会把当前线程阻塞掉。当有一个或多个流有I/O事件时,就从阻塞态中醒来。于是,代码调整成这样:
while true:
select(open_connections)
for x in open_connections:
if has_new_input(x):
process_input(x)
调整之后,如果没有I/O事件产生,我们的程序就会阻塞在select处。但这样依然有个问题:我们从select那里仅仅知道,有I/O事件发生了,但却并不知道是那几个流(可能有一个,多个,甚至全部),我们只能无差别进行轮询,找出能读出或写入数据的流,对他们进行操作。使用select,我们有O(n)的无差别轮询复杂度,同时处理的流越多,每一次无差别轮询时间就越长。
epoll被用来优化select的问题,它会将哪个流发生了怎样的I/O事件通知我们。此时我们对这些流的操作都是有意义的(复杂度降低到了O(k),k为产生I/O事件流的个数)。最后,代码调整了这样:
while true:
active_conns = epoll(open_connections)
for x in active_conns:
process_input(x)
I/O多路复用
多路复用的本质是同步非阻塞I/O,多路复用的优势并不是单个连接处理的更快,而是在于能处理更多的连接。类似服务对外提供了一个批量接口。
I/O编程过程中,需要同时处理多个客户端接入请求时,可以利用多线程或者I/O多路复用技术进行处理。 I/O多路复用技术通过把多个I/O的阻塞复用到同一个select阻塞上,一个进程监视多个描述符,一旦某个描述符就位, 能够通知程序进行读写操作。因为多路复用本质上是同步I/O,都需要应用程序在读写事件就绪后自己负责读写。 最大的优势是系统开销小,不需要创建和维护额外线程或进程。
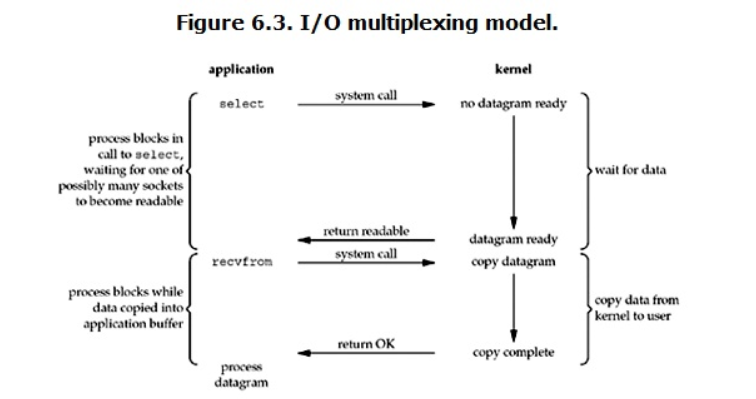
结合多路复用,来看一下异步非阻塞I/O:
对比异步非阻塞I/O,读请求会立即返回,说明请求已经成功发起,应用程序不被阻塞,继续执行其它处理操作。当read响应到达,将数据拷贝到用户空间,产生信号或者执行一个基于线程回调函数完成I/O处理。应用程序不用在多个任务之间切换。
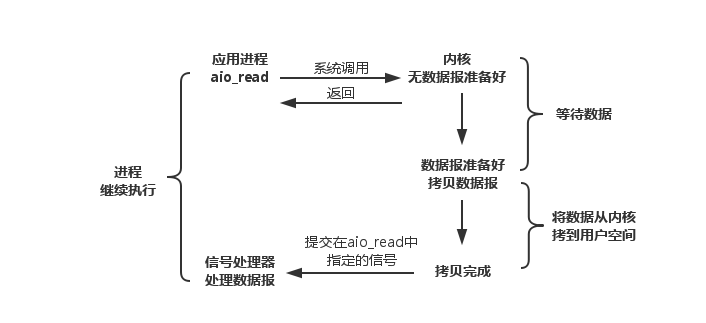
可以看出,阻塞I/O在wait for data和copy data from kernel to user两个阶段都是阻塞的。而只有异步I/O的receivefrom是不阻塞的。
epoll
epoll的系统调用方法包括:epoll_create、epoll_ctl、epoll_wait,
epoll_create创建一个epoll对象:
epollfd = epoll_create()
epoll_ctl往epoll对象中增加/删除某一个流的某一个事件:
// 有缓冲区内有数据时epoll_wait返回
epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN);
//缓冲区可写入时epoll_wait返回
epoll_ctl(epollfd, EPOLL_CTL_DEL, socket, EPOLLOUT);
epoll_wait等待直到注册的事件发生。
Go语言
go语法上提供了select语句,来实现多路复用。select语句中可以监听多个channel,只要其中任意一个channel有事件返回,select就会返回。否则,程序会一直阻塞在select上。通过结合default,还可以实现反复轮询的效果。
select {
case <-tick:
// Do nothing.
case <-abort:
fmt.Println("Launch aborted!")
return
}
netpoll_epoll.go中实现的epoll方法,依次通过调用netpollinit、netpollopen、netpoll来实现。可能是调用太清晰了,整个文件除了下面的注释外,再也没有别的有效注释了。
// polls for ready network connections
// returns list of goroutines that become runnable
func netpoll(block bool) *g {}
epoll的LT和ET模式
epoll的两种触发模式:Level triggered和Edge triggered
两者的差异在于level-trigger模式下只要某个socket处于readable/writable状态,无论什么时候进行epoll_wait都会返回该socket。而edge-trigger模式下只有某个socket从unreadable变为readable或从unwritable变为writable时,epoll_wait才会返回该socket。
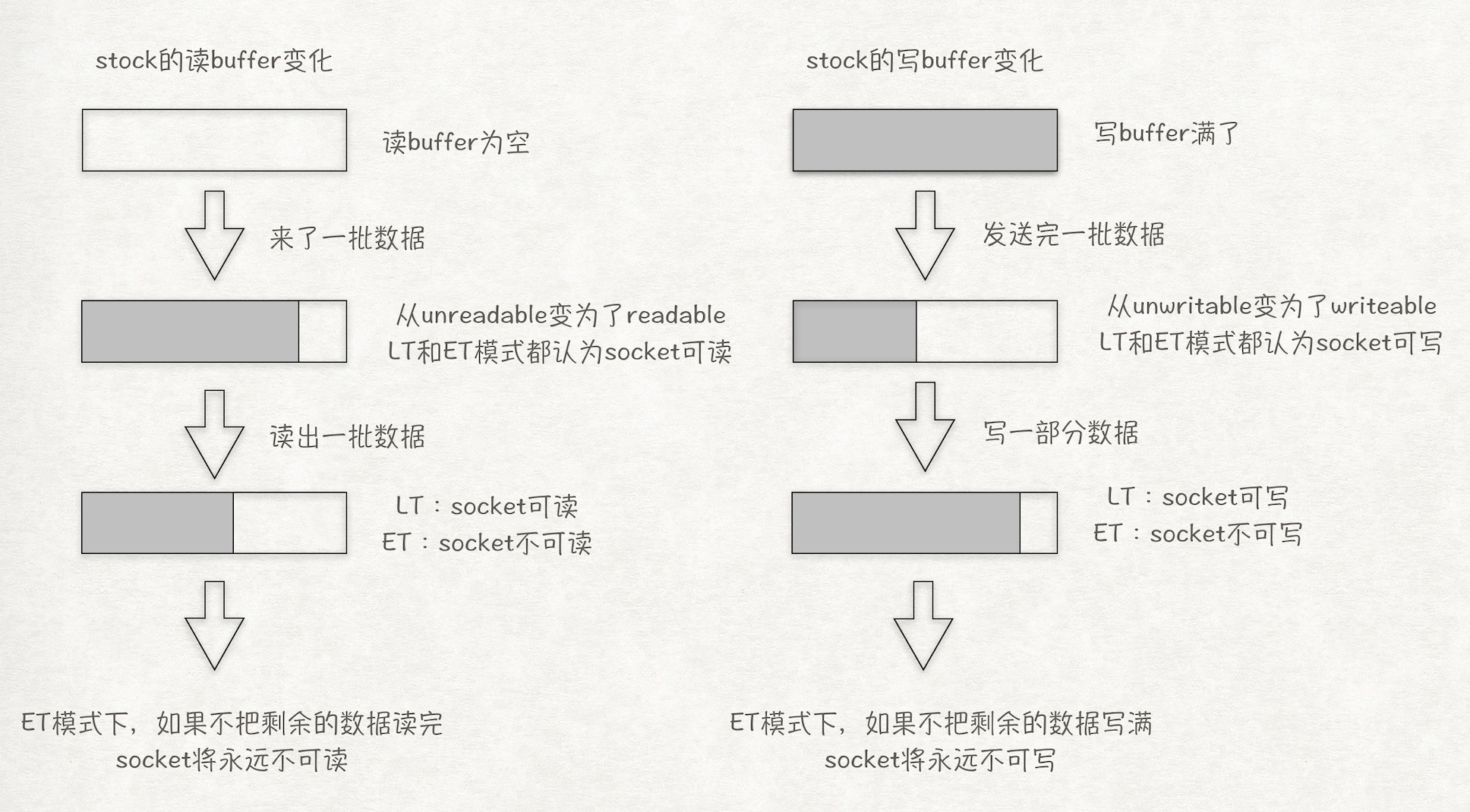
所以, 在epoll的ET模式下, 正确的读写方式为:
- 读: 只要可读, 就一直读, 直到返回0, 或者 errno = EAGAIN
- 写: 只要可写, 就一直写, 直到数据发送完, 或者 errno = EAGAIN
关于这两种模式,博客Epoll is fundamentally broken 1/2也做了解释,它通过内核负载均衡accept()的例子来进行说明。这里也尝试简单介绍一下,因为例子读起来确实有趣,也方便我们加深理解。
在开发一个高吞吐量的HTTP Server(服务大量的短连接)时,因为请求量非常大,我们希望充分利用计算机多核资源,将accept操作分配到不同的核来并发处理。但想要实现连接的负载均衡,直到内核4.5版本才变成可能。
水平触发 - 不需要的唤醒
一个天真的解决办法是:我们全局创建一个epoll对象,多个工作线程来同时wait它。但是level triggere模式存在“惊群现象”(前提:没有给epoll指定具体的flag),对于每一个到来的新连接,所有的工作线程都会被唤醒。
Kernel: 接收到一个新连接
Kernel: 通知正在等待的线程`Thread A`和`Thread B`
Thread A: epoll_wait()返回.
Thread B: epoll_wait()返回.
Thread A: 执行`accept()`, 操作成功.
Thread B: 执行`accept()`, 操作失败,返回`EAGAIN`.
在这个过程中,唤醒Thread B是完全没有必要的,并且浪费了系统资源。所以,level-triggered模式在水平扩展上非常差。
边缘触发 - 不需要的唤醒和饥饿
我们已经介绍了level-triggered模式的问题,那么edge-triggered模式会不会做到更好呢?
并不是,下面是可能的运行情况:
Kernel: 收到一个新连接,此时线程`A`和`B`都在等待。因为现在是"edge-triggered"模式,所以仅仅会有一个线程被通知,假设是`A`.
Thread A: `epoll_wait()`返回.
Thread A: 执行`accept()`, 操作成功.
Kernel: accpet队列变空, `event-triggered socket`状态由"readable"变为"non readable"
Kernel: 接收到第二个连接.
Kernel: 现在只剩下线程`B`在执行`epoll_wait()`. 于是唤醒`B`.
Thread A: 继续执行`accept()`,原本希望返回`EAGAIN`,但是返回了第二个连接
Thread B: 执行`accept()`, 返回`EAGAIN`.
Thread A: 继续执行`accept()`, 返回`EAGAIN`.
上述过程中,B的唤醒是完全不需要的。而且,B会感到非常困惑。此外,edge-triggered模式也很难避免线程饥饿的情况
Kernel: 接收到两个连接,此时`A`和`B`都在等待. 假设`A`收到通知.
Thread A: `epoll_wait()`返回.
Thread A: 执行`accept()`, 操作成功
Kernel: 接收到第3个连接.`event-triggered socket`是"readable"状态, 现在依然是"readable".
Thread A: 必须执行`accept()`, 希望返回`EGAIN`, 但是返回了第三个连接.
Kernel: 接收到第4个连接.
Thread A: 继续执行`accept()`, 希望返回`EGAIN`, 但是返回了第四个连接.
在这个例子中,event-triggered socket状态只是从non-readable变为了readable。因为在edge-trigger模式下,内核只会唤醒其中一个线程。所以,例子中所有的连接都会被线程A处理,负载均衡无法实现。
SELECT
select和poll类似,主要操作包括两步:
- 传递给它们一个文件描述符集合
- 它们返回集合中的哪些可以进行读/写操作
程序调用select将会被阻塞,直到存在可用的文件描述符,或者执行超时。当返回成功时,各个fd_set集合会被修改为仅包含可用的文件描述符。所以,每次调用select还需要重置它的参数列表。
函数解释:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
nfds被设置为三个集合中最高的文件描述符数值+1,这表明每个集合中的文件描述符都会被检查,直到达到这个限制。
三个独立的文件描述符集合会被监控:readfds中的文件描述符是否可读,writefds是否有空间可写,exceptfds是否异常的情况。在函数退出时,文件描述符集合会被修改,来标识被改变状态的文件标识符。如果没有文件描述符需要被监控,这三个集合都可以指定为NULL。
当这三个集合都为NULL,而timeval不为空时,等价于系统执行sleep的效果。如果timeval结构体的两个字段都为0,就类似于轮询的效果了。以下是timeval的结构体:
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};
在select中有4个宏函数被提供:FD_ZERO()用于清除一个集合,FD_SET()和FD_CLR()用来增加和删除一个给定的描述符,FD_ISSET()用来检查文件描述符是否是集合的一部分。
为什么我们在io操作中不使用select,而选择使用epoll?
节选自Async IO on Linux: select, poll, and epoll的描述:
On each call to select() or poll(), the kernel must check all of the specified file descriptors to see if they are ready. When monitoring a large number of file descriptors that are in a densely packed range, the timed required for this operation greatly outweights [the rest of the stuff they have to do]
参考文章: