跳表
跳表是基于链表的,在链表的基础上加了多层索引结构。在 Redis 的有序集中就使用了跳表,但 Redis 在跳表的基础上做了定制。
跳表拥多层链表,最底层的链表包含所有的数据。越往上层,链表的节点也越稀疏。但是,高层的节点一定是底层的节点。下面是一个跳表的示例:
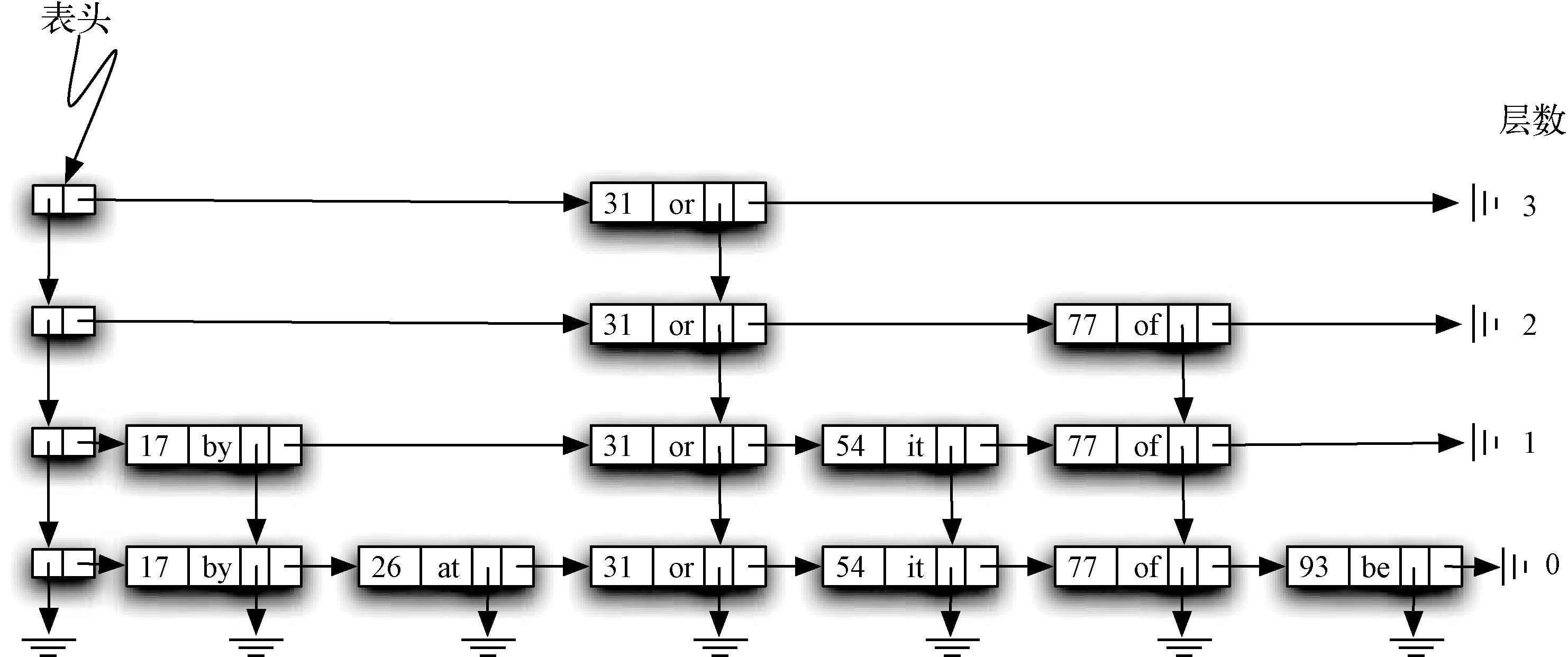
表头节点就是图中最左边的那一列,它的每个节点都只包含两个引用( down 和 nex t),down指向下层的表头节点,next指向同层的数据节点。
而数据节点由4部分组成,比如层3中唯一的数据节点,31表示节点的键,or 表示节点的值,同时也包含两个引用( down 和 next)。跟表头节点 down 区别在于,down 指向的数据类型是数据节点。
需要特别指出的是,针对数据中的每个节点,它应该创建几层的结构,是算法随机决定的。平均而言,1/2个元素有两个索引,1/4个元素有三个索引,以此类推。
跳表是如何实现的查找呢?从表头开始搜索键为54的数据,标红的星星表示查找节点的过程:
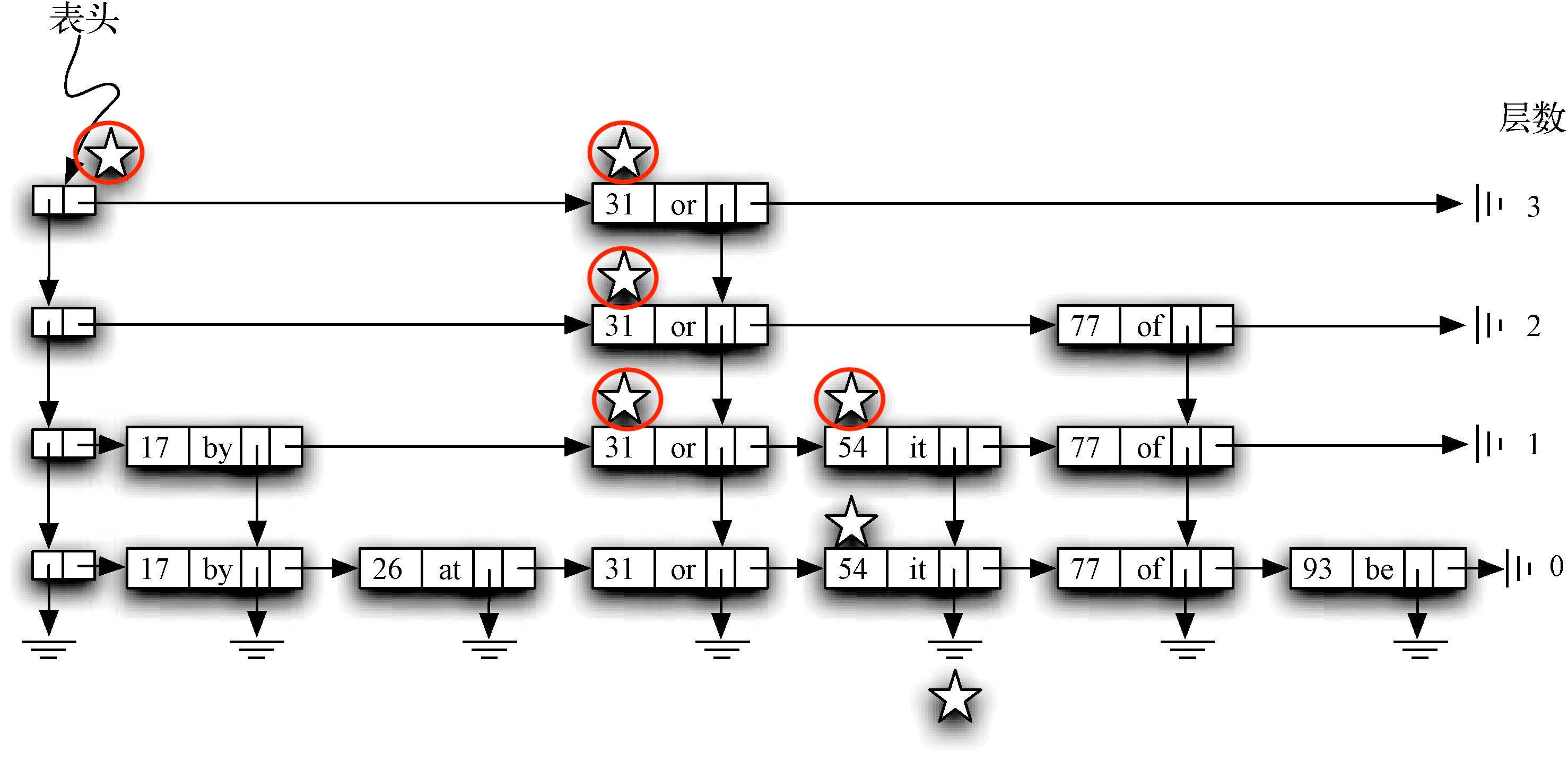
- 从表头节点开始搜索,头节点的next指向键为31的节点,且31小于54,然后继续判断31节点的next节点,发现引用为 nil。开始通过down向下一层(层2)搜索。
- 继续获取层2中键为31的节点的next节点,发现值等于77,数据大于54,则继续向下一层(层1)查找。
- 继续读取层3中键值为31节点的next,发现值为54,数据找到了,结束本次查询。
插入是如何实现的呢?为了方便,我们以插入键值65为例。我们需要找到每一层插入65节点的位置。图中带星星的就是可能要插入的位置。前面提到过,数据节点的层是随机确定的,在插入65节点时,这条规则当然需要遵守。
- 我们在层0进行插入,将65插入到54的后面
- 判断是否要建立层1节点,如果需要,将65插入到层1的54之后
- 以此类推