Go 调度模型(二)
Posted by 付辉 on Saturday, March 30, 2019 共2193字
真的猛士,敢于直面惨淡的人生,敢于正视淋漓的鲜血。这是怎样的哀痛者和幸福者?然而造化又常常为庸人设计,以时间的流驶,来洗涤旧迹,仅使留下淡红的血色和微漠的悲哀。在这淡红的血色和微漠的悲哀中,又给人暂得偷生,维持着这似人非人的世界。我不知道这样的世界何时是一个尽头!
有一种感觉,Go调度模型可能还得再来几篇博客,才能真正读出感觉来。现在还是一个门外汉。越是深入了解,越觉得知之甚少,后背发凉。
OS调度结构
Go Runtime实现了自己的调度策略,从OS调度结构的演变来看,调度思想都是相似的。当然,我始终觉得设计背后的思想才是整个系统的核心。思想从无到有、从中心化到去中心化、从单任务到并行多任务,当然这肯定不是调度策略的专利,在很多场景都有这种思想的体现,比如分布式设计。
那为什么我还是没有一眼看出来呢,可能是阅历太少,思考的深度不够,积极接受现状,懒于了解历史吧。不过,越是去了解,就会发现不会的太多,思维发散的太广,难以为继。
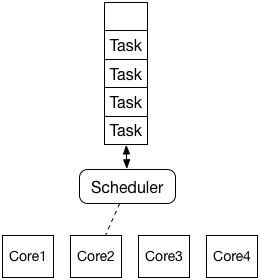
single scheduler
存在一个全局的任务队列和一个全局的调度器,因为整个过程不需要加锁,所以单核吞吐量很高,但无法充分利用多核资源。
有点类似于:给一个数据表中的所有用户PUSH消息,虽然我们有10台服务器,但我们只在其中一台服务上执行该任务。优点是设计开发简单,缺点是没有充分利用资源,效率不高。
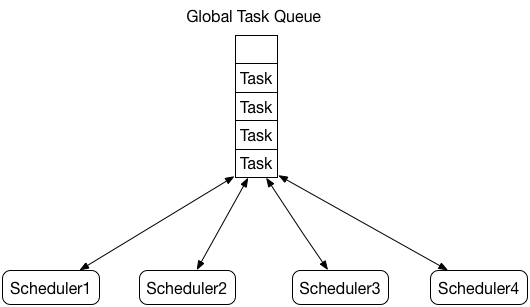
multi scheduler with global queue
多个调度器共享一个全局的任务队列,该模型需要频繁的对任务队列进行加锁,并发性能存在明显的瓶颈。这同时让我想起了Go的并发问题中介绍的例子,加锁保证了计算的正确性,但却牺牲了效率。当然,这不仅仅是调度系统会面临的问题,比如本地缓存BigCache也遇到了同样的问题。
还接着上面的例子说,当在多台服务器上都启动Task执行任务时,为了避免同一个用户不被重复PUSH多次,势必也面临着对单条记录加锁的问题。
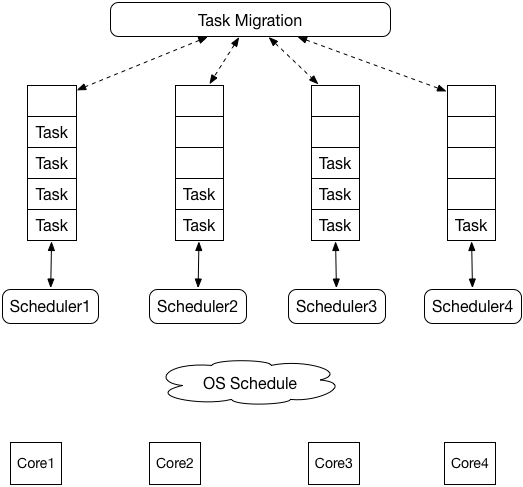
multi scheduler with local queue
给每个调度器分配一个本地的任务队列,这样调度器就可以无锁的操作本地任务队列,显著减少锁竞争,提高多核下的调度效率。同时还要保证让各个调度器随时都有事情可做,所以也存在一些任务迁移或者任务窃取的方案。到了这里,我们就已经看到了Go Scheduler的雏形。其实思维很简单,将全局的任务队列划分成多个小的任务队列,各个调度器处理自己的任务队列,跟Database Sharding异曲同工。
继续上面的例子,我们只需要给各个服务器分配用户表的小块数据,当Task执行完分配的数据块后,再去请求新的数据块就可以了。
GPM
现在提到Go Scheduler就会直接想到GPM,但之前的设计里Scalable Go Scheduler Design Doc其实并不存在P。P的引入直接将调度模型由multi scheduler with global queue跨越到multi scheduler with local queue。
- 每个
Goroutine需要对应一个G结构体,而G保存了当前Goroutine的运行堆栈和状态信息。Goroutine通过G中保存的信息可以执行或恢复执行。 P是专门被引入用来优化原始Go调度系统所抽象的逻辑对象,操作系统并不知道P的存在。对M而言,P提供了其执行的相关环境、以及Goroutine的任务队列等。M是OS线程的抽象,是物理存在的。M只有和P绑定之后,才可以执行G代码。M本身也不会保存G的状态,在需要任务切换时,M会将堆栈状态保存回G中,任何M都可以根据G中的信息恢复执行。
M阻塞
当M准备执行Goroutine时,首选需要关联一个P,然后从P的队列中取出一个G来执行。如果G中执行的代码使M发生阻塞,比如唤起系统调用。那么M将会一直阻塞,直到系统调用返回。此时全局空闲M队列的另一个M会被唤醒,同时,阻塞状态的M会与P解绑。这样做也是为了保证其他G不会因为缺少M而被阻塞执行。
但如果Goroutine在channel通讯过程中发生阻塞,M并不会展示相似的阻塞行为。因为OS并不了解channel 的执行机制,channel是被Go Runtime来处理的。如果一个Goroutine在channel通讯上发生了阻塞,那没有任何理由让运行它的M也阻塞。这种情况下,G的状态会被设置为等待,M会继续执行别的Goroutine。当G重新变成可运行状态时,等待别的M去执行。
P的改进
原始Go的调度并没有P,仅有G、M以及Sched。当时系统只存在一个全局的G队列,通过Sched锁来进行并发控制。存在的问题有:
- 调度的执行依赖全局的
Sched锁,修改全局的M队列和G队列、或者其他全局的Sched字段都需要加锁 M的内存问题,执行的内存是跟M相关联的。但即使M并不执行G代码,它也会申请2MB的MCache空间,而这些空间只有M在执行G时才需要。同时,一个阻塞中的M也是不需要MCache的。- 系统调用不够清晰,
M在执行中会频繁阻塞和恢复,浪费CPU时间 M之间频繁的传递G,而不是选择自己执行它,这增加了系统的额外负载。每个M必须能够执行任何可运行的G,特别是刚刚创建了G的M。
P引入之后,从之前的M和Sched中抽取了部分字段,这样做带来了很多好处:
MCache就被移动到了P中,而系统最多存在GOMAXPROCES个P,解决了不必要的内存浪费问题G freelist被移动到P中,每个P都有了一个可运行的本地G队列。本地G队列缓解了全局Sched锁的问题。- 当一个
G被M创建,它被追加到对应P的本地队列末尾,以保证每个G都能被执行。
参考文章: